
Currently Empty: ₹0.00
Explore types of distributed data storage and its impact on modern DBMS systems in this comprehensive guide by Aktu Hub.
1. Introduction to Distributed Data Storage in DBMS
Distributed Data Storage in DBMS represents a paradigm shift in how data is stored, accessed, and managed across multiple servers or locations. Unlike traditional databases that rely on a single system, distributed databases leverage multiple nodes to enhance data accessibility, reliability, and scalability.
The importance of distributed systems has surged with the advent of big data, cloud computing, and globalized information access. In this context, understanding distributed data storage is crucial for database administrators, software engineers, and IT professionals.
2. Key Concepts of Distributed Data Storage
At the heart of distributed data storage are concepts such as data distribution and replication. These mechanisms ensure that data is available across multiple nodes, minimizing the risk of data loss and improving access speed.
Data distribution refers to the method of partitioning data across different servers, while replication involves creating multiple copies of data to ensure redundancy. Balancing consistency (ensuring all nodes reflect the same data state) and availability (data is accessible even during server failures) is a critical challenge in distributed systems.
3. Architecture of Distributed Databases
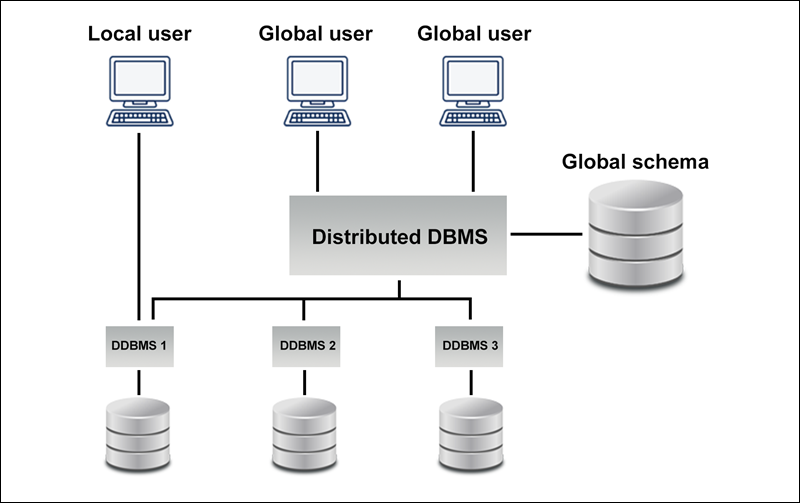
Distributed databases can be categorized based on their architecture: centralized and distributed. Centralized databases store all data in a single location, while distributed databases spread data across multiple sites.
Components of a distributed database system include data nodes, query processors, and transaction managers. Together, these elements ensure data is stored, processed, and retrieved efficiently across the network.
4. Data Distribution Strategies
Data can be partitioned in several ways to optimize performance and reliability:
- Horizontal Partitioning divides tables by rows, distributing subsets of data across different nodes.
- Vertical Partitioning splits tables by columns, distributing different attributes across nodes.
- Hybrid Partitioning combines both horizontal and vertical approaches to leverage their respective advantages.
5. Replication Techniques in Distributed DBMS
Replication is essential for maintaining data availability and resilience. It can be implemented in two main forms:
- Synchronous Replication ensures all copies of data are updated simultaneously, providing strong consistency.
- Asynchronous Replication allows updates at different times, which can lead to temporary inconsistencies but improves system availability.
Popular models include master-slave replication, where a primary server handles updates, and peer-to-peer replication, where each node can act as a master.
6. Consistency Models in Distributed Systems
Distributed systems employ various consistency models to balance performance and data accuracy:
- Strong Consistency ensures all nodes have the same data at any given time.
- Eventual Consistency allows temporary inconsistencies, with the system eventually converging to a consistent state.
- Causal Consistency tracks causal relationships between operations to maintain a logical order.
7. Data Storage Models
Distributed systems use different storage models, each suited to specific data types and use cases:
- Relational Databases (RDBMS) rely on structured data and SQL.
- NoSQL Databases handle unstructured data, offering flexibility in schema design.
- Object-Oriented and Document-Based Models cater to applications requiring complex data types and hierarchical structures.
8. Scalability and Performance in Distributed Storage
Scalability is a defining feature of distributed databases. Techniques such as load balancing and sharding distribute workloads evenly across servers, ensuring efficient resource utilization.
Indexing and query optimization are critical for maintaining performance in distributed environments, enabling fast data retrieval despite the system’s complexity.
9. Fault Tolerance and Reliability
Fault tolerance is achieved through mechanisms like fault detection and recovery. These systems automatically identify and rectify issues, minimizing downtime.
Data backup and disaster recovery strategies are crucial for protecting against data loss, ensuring business continuity even in catastrophic events.
10. Security Challenges in Distributed Data Storage
Security in distributed databases involves several layers:
- Data Encryption protects data at rest and in transit.
- Secure Communication Protocols ensure safe data exchange across nodes.
- Access Control and Authentication prevent unauthorized access, safeguarding sensitive information.
11. Use Cases and Applications
Distributed data storage finds applications in diverse domains:
- Cloud Storage services like Google Drive and Dropbox rely on distributed databases for scalability and accessibility.
- Big Data Analytics leverages distributed systems to process vast datasets efficiently.
- IoT environments use distributed storage to manage data from numerous connected devices.
12. Popular Distributed DBMS Systems
Several distributed DBMS systems have gained prominence:
- Apache Cassandra and MongoDB are widely used for their scalability and flexibility.
- Traditional systems like MySQL and PostgreSQL have also adapted to support distributed architectures, offering a balance of reliability and innovation.
13. Advantages of Distributed Data Storage
Distributed data storage offers numerous benefits:
- Enhanced Accessibility ensures users can access data from multiple locations.
- Scalability allows systems to handle growing amounts of data without performance degradation.
- Cost Efficiency is achieved through the use of commodity hardware and cloud infrastructure.
14. Challenges and Limitations
Despite its advantages, distributed data storage presents several challenges:
- Network Latency can affect performance, especially in geographically dispersed systems.
- Data Synchronization issues may arise due to inconsistent updates across nodes.
- Management Complexity increases with the system’s scale and intricacy.
15. Future Trends in Distributed Data Storage
The future of distributed data storage is bright, with advancements in:
- Emerging Technologies like blockchain, which offers decentralized and secure data storage.
- AI and Machine Learning are set to play pivotal roles in optimizing data distribution and management.
FAQs
- What is Distributed Data Storage in DBMS?
- It refers to storing data across multiple servers to improve reliability, scalability, and performance.
- How does replication work in distributed databases?
- Replication involves creating multiple copies of data across different nodes to ensure data availability and fault tolerance.
- What are the common challenges in distributed data storage?
- Challenges include network latency, data synchronization issues, and increased management complexity.
- Why is fault tolerance important in distributed systems?
- Fault tolerance ensures that the system remains operational even when some components fail, thus maintaining data availability.
- How do distributed databases ensure data security?
- Through encryption, secure communication protocols, and strict access control mechanisms.
- What are the benefits of using NoSQL databases in distributed systems?
- NoSQL databases offer flexibility in handling unstructured data, scalability, and ease of integration with modern applications.
Conclusion
Distributed Data Storage in DBMS is a cornerstone of modern database management, offering unmatched scalability, reliability, and performance. As technology evolves, the role of distributed systems will only grow, driving innovation in data storage and management.



